
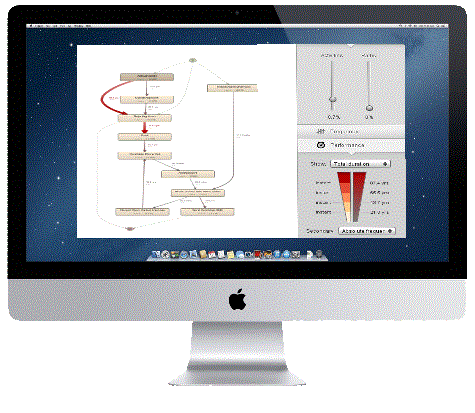



We gebruiken “leading edge” technieken en tools die ons in staat stellen processen te visualiseren en te analyseren. Als resultaat heeft u een duidelijk en op feiten gebaseerd beeld van de doorstroom van de processen. Deze nieuwe inzichten kunnen we weer gebruiken om de problemen die zichtbaar zijn geworden aan te pakken en op te lossen.
Vanaf dit punt wordt er geld verdiend. Door de nieuwe inzichten ben u in staat om knelpunten in het proces te vinden. Loops en ongewenste processtappen worden zichtbaar en samen met de proceseigenaren en onze -of uw- Lean Six Sigma experts werken we aan het elimineren van de problemen en de inefficiënties. En door het proces te blijven monitoren kunnen we het effect van de uitgevoerde optimalisatiemaatregelen snel inzichtelijk maken, zodat het resultaat van de optimalisatie-acties meteen duidelijk wordt.
Iets meer achtergrond
Proces mining begint bij de applicaties die de bedrijfsprocessen ondersteunen. SAP, de Purchase to Pay software, de helpdesk applicatie, etc. Voorwaardelijk voor succes is dat de applicaties die we willen onderzoeken event informatie opslaan in logfiles. Deze logfiles (data sources) die we kunnen gebruiken om de Proces Mining algoritmes op los te laten zijn bijvoorbeeld spreadsheets, databases, transaction logs, audit trails, etc. De meeste applicaties voor administratieve taken, geautomatiseerde processen, workflowsystemen of support systems loggen proces data in audit trails of in zogenaamde “transaction logs”. Wij gebruiken deze logfiles om van het bijbehorende proces de modellen te genereren die het proces representeren en de procesflow visualiseren. Standaard formaten voor de data die gebruikt kunnen worden binnen het mining proces zijn MXML (Mining eXtensible Markup Language) en XES (eXtensible Event Stream). XES is door de IEEE Task Force on Process Mining gekozen als het standaard formaat voor het loggen van events. Maar wat we het meest tegen komen zijn logfiles die in CSV (Comma-Separated Values) of XLS (Microsoft Excel) formaat aangeboden worden en ook die kunnen prima gebruikt worden om te minen, als tenminste de minimaal benodigde informatie in de file aanwezig is.
We gaan op zoek naar anomaliteiten, loops, bypasses, bottlenecks, we onderzoeken specifieke cases, creëren viewpoints, bouwen filters en we doen de statistiek. Een van de eerste dingen die we vaak doen is een “conformance check”. Bij een conformance check kijken we in hoeverre het “ideale proces”, de blauwdruk, overeen komt met de fact based proces flow die door de algoritmes bepaald is (die door optimistische geesten ook wel de Werkelijkheid genoemd wordt). Het verrassende is: de verschillen tussen hoe men denkt dat het proces eruit ziet, en het gegenereerde proces model zijn in verre weg de meeste gevallen groter dan verwacht.


DATA REQUIREMENTS
Het event log dat we nodig hebben om process mining te kunnen doen heeft drie simpele karakteristieken. -1- De logfile moet CaseID’s bevatten. Een CaseID is het “onderwerp”. De CaseID staat voor het ding dat het proces doorloopt: een trouble ticket door het helpdeskproces, een rekening door het administratieve proces, een container door een logistiek proces, een printplaat door een productieproces, etc. -2- De logfile moet de activiteiten bevatten die in het proces worden uitgevoerd, dus de proces-stappen. -3- De logfile moet een timestamp bevatten per activiteit. Dus als we bijvoorbeeld een aanvraag door een vergunningsysteem willen volgen dat is het aanvraagnummer de CaseID, de diverse stappen in het proces zijn de activiteiten (“aanvraag aangemeld”, “aanvraag in behandeling”, “aanvraag naar het kastje”, “aanvraag naar de muur”, etc.. en als laatste willen we per activiteit een time-stamp.
Uit het voorbeeld hierboven (van Fluxicon) kan je zien dat zelfs eenvoudige proces-gerelateerde analyses, zoals het meten van de frequentie van varianten in de proces flow, of de tijd tussen activiteiten, zo goed als onmogelijk is als je standaard tools zoals Excel gebruikt. Procesregels zijn verspreid over meerdere rijen in de spreadsheet (hoe je ook sorteert) en ze kunnen pas echt goed met elkaar worden gelinkt als je een proces-georiënteerd Meta model hebt.
Ook hier geldt: hoe meer informatie, hoe beter het is. Veelal bevat het logfile nog veel meer contextuele informatie over locatie, klantnummer, afdeling, soort aanvraag, etc. Hoe meer additionele informatie er beschikbaar is die kan worden toegevoegd aan de spreadsheet hoe meer “views” op het proces we kunnen maken. Zo zouden we bijvoorbeeld verschillen in de manier van werken tussen twee afdelingen zichtbaar maken als aan de event data ook afdelingsinformatie is toegevoegd. Door informatie te linken (klonteren) zijn we in staat geweest om inzichtelijk te maken waarom de ene afdeling succesvoller is dan de andere, waarom sommige trouble tickets zelden de afgesproken oplostijd halen, etc.